机器学习中常用的数学基础
P1高斯分布(正态分布)
自然界产生的数据分布一般是正态分布(如年龄、身高、体重等),故当对数据不清楚其潜在的结构、即对数据潜在分布模式不明确时,近似采用正态分布。
在机器学习中,目标通常是使得数据线性可分,甚至意味着将数据投影到更高维空间,找到一个可拟合的超平面(如SVM核,神经网络层,softmax等)。原因是“线性分界通常有助于减少方差variance而且是最简单,自然和可理解的”,同时减少数学、计算的复杂性。同时,当我们聚焦线性可分时,通常可以很好减少异常点、影响点和杠杆点的作用。因为超平面是对影响点和杠点(异常点)非常敏感。举个例子,在二维空间中,我们有一个预测器predictor(X),和目标值(y),假设X和y是很好的正相关。在这个情形下,假设X是正态分布,y也是正态分布,那么你可以拟合到一条很直的线,相比边界点(异常点,杠杆点),很多点都集中在线的中间,所以这个预测回归线在预测未知数据时,降低方差的影响。

数学基础
P2有偏估计&无偏估计
- 本质来讲,无偏/无偏估计是指估算统计量的公式,无偏估计就是可以预见,多次采样计算的统计量是在真实值左右两边。类似于正态分布的钟型图形。比如对于均值μ估计。一定有的比μ大,有的比μ小。那么对于有偏估计,就是多次采样,估算的统计量将会在真实值的一侧(都是大于或者都是小于真实值)无偏估计并不一定比有偏估计更加”有效”,因为所谓估算有效是指更加靠近真实值。

数学基础
P3二次型
- 二次型:n个变量的二次多项式称为二次型,即在一个多项式中,未知数的个数为任意多个,但每一项的次数都为2的多项式。线性代数的重要内容之一,它起源于几何学中二次曲线方程和二次曲面方程化为标准形问题的研究。二次型理论与域的特征有关。PCA跟特征值和特征向量有关,应该跟二次型有关。

数学基础
P4二次型 && P5:
- PCA主成分分析用到实对称阵的相似对角化。PCA的目的是降噪和去冗余,是一种常用的数据分析方法。PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。

数学基础
P6协方差(Covariance)
- 在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
- 协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。 如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。用于机器学习中衡量多个特征之间的关系。

数学基础
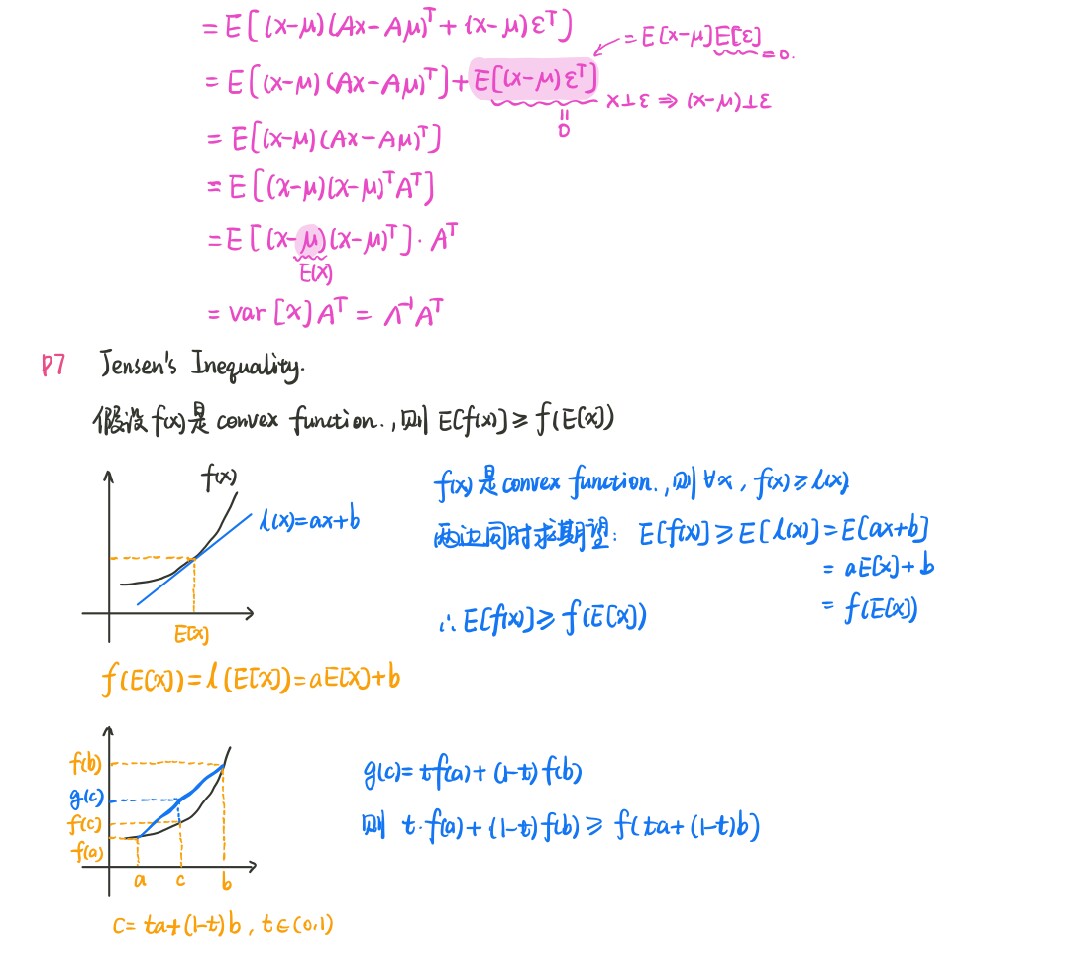
P7Jensen不等式(Jensen’s inequality)
- 在概率论、机器学习、测度论、统计物理等领域都有相关应用。在机器学习领域,用Jensen不等式用来证明KL散度大于等于0,EM算法推导最后也用到了Jensen不等式。
数学基础
